
Some of these foundational models are amazing
A snapshot of the progress, demo links and more!

Introduction
This article is a application-oriented attempt to wrap my head around recent developments in remote sensing and geospatial foundational models, focusing on research published within the last five years, trying to identify gaps and opportunities in my view and sharing my experiments. The sections are organized into foundational models intro, applications, benchmarks, and key resources.
Foundational Models in Remote Sensing and Geospatial Science
Remote sensing foundation models mostly refer to large models, mostly built through self supervised learning, trained on diverse remote sensing data (RGB,MX,HX, SAR,LiDAR,etc.). A nice, helpful taxonomy is given by Xiao et. al. is shown below.
Thanks for reading Mostly Stable, Slightly Inclined ! Subscribe for free to receive new posts and support my work.

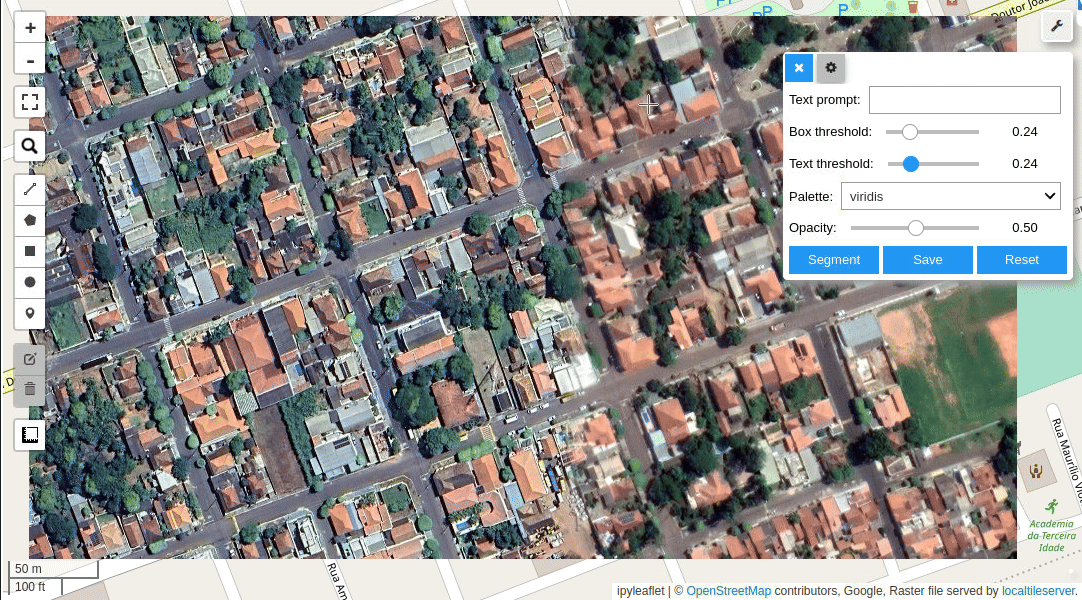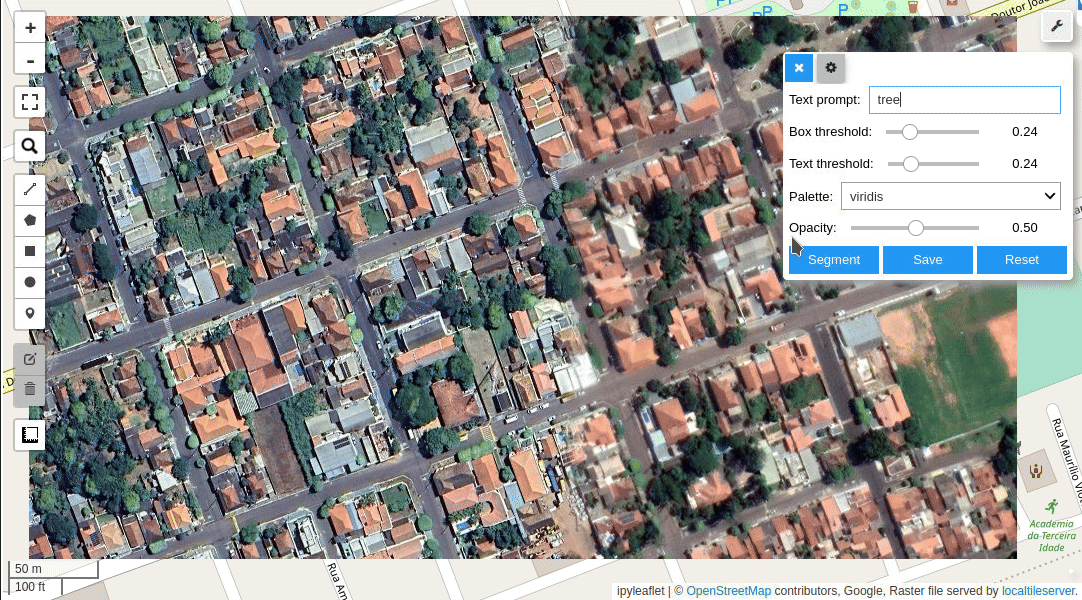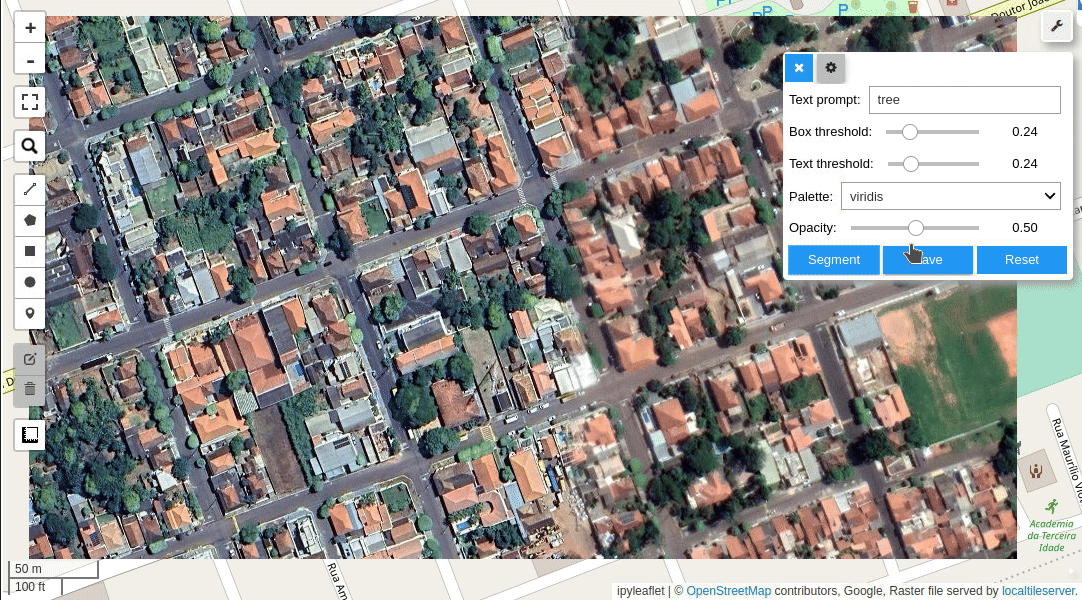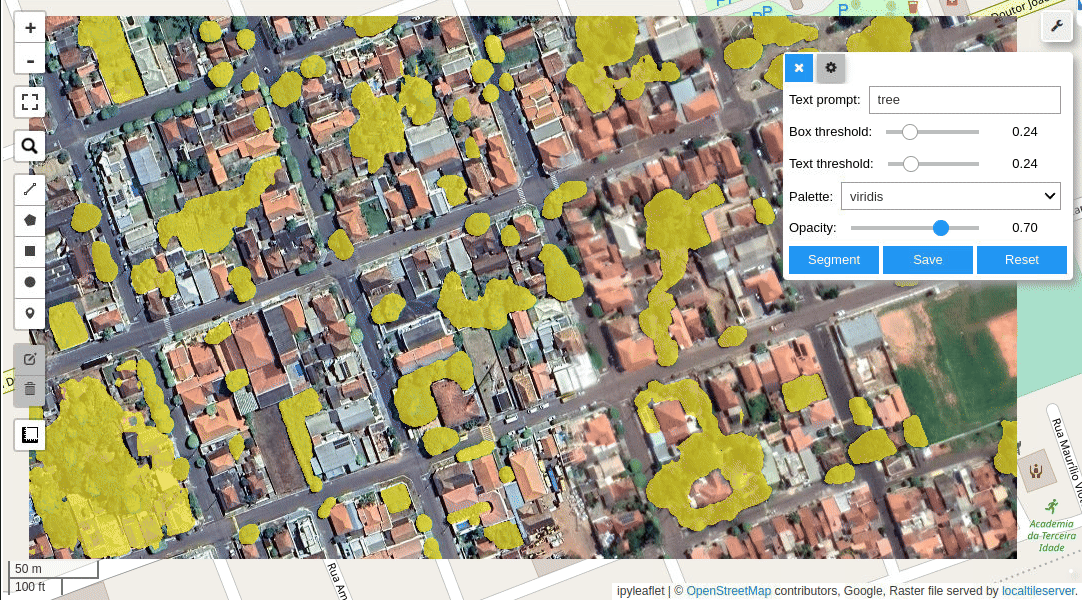
The Visual Foundation Models (VFMs) comprise Pre-trained models learning transferable representations from unlabeled data through contrastive (similarity) and Masked Image Modeling (MIM) and finetuning models to improve performance. Meta’s Segment Anything Model (SAM) has been adapted to Samgeo which can interact through text and location pin prompts save segmented areas with geospatial data like GeoTIFF raster data and GPKG vector data.
The Vision Language models (VLMs) integrate vision and text data and involve captioning, Visual Question Answer, Visual Grounding, Scene Classification, Object Detection, Region Caption and Multi-round conversation as shown by this excellent graphic from generative VLM EarthGPT (utilitizing Vision Transformers, LLAMA-2 and multiple task-specific remote sensing datasets).

Many Visual-text models are extensions of CLIP in the remote sensing domain. We did a test of the CLIP-based RS-ICD image captioning model and reported our learnings in a previous blog. Github user Jack-bo1220 has compiled many Remote Sensing Vision-Language Foundation Models here. Visual-location models like SatCLIP have a location encoder summarize the characteristics of any given location (latitude,longitude) using CNN and ViT inferred visual patterns for a downstream task like predicting air temperature.
SkyCLIP
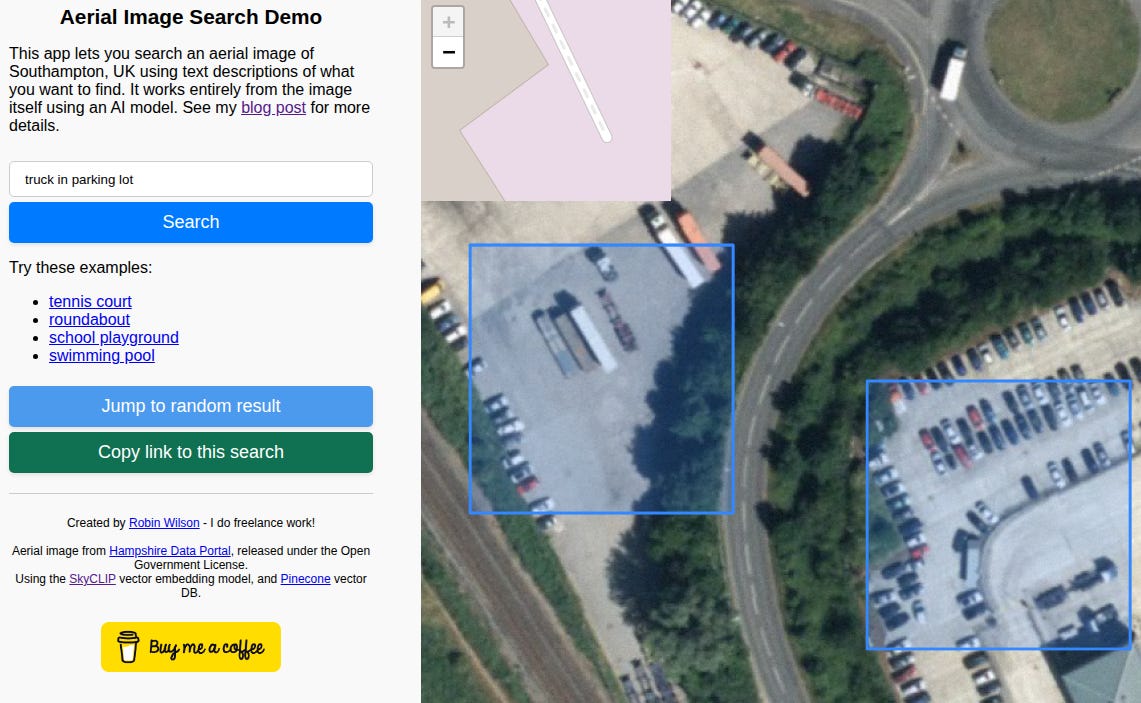
Tiny Demo 1: I found this demo by RT Wilson based on SkyCLIP model really the first fun thing to try out. Quoting the blogpiece:
An embedding model lets you turn a piece of data (for example, some text, or an image) into a constant-length vector – basically just a sequence of numbers. In this case, I’m using the SkyCLIP model which produces vectors that are 768 elements long. One of the key features of these vectors are that the model is trained to produce similar vectors for things that are similar in some way. For example, a text embedding model may produce a similar vector for the words “King” and “Queen”, or “iPad” and “tablet”. The ‘closer’ a vector is to another vector, the more similar the data that produced it.
Turns our queries like “truck in parking lot” are fairly high precision although I am not sure about the recall:
SAM3 Geo
Tiny Demo 2:
I made a colab notebook for SAM3 Geo, a fresh unified foundation model for promptable segmentation in images and videos for a test location in Bangalore, India. It can detect, segment, and track objects using text or visual prompts such as points, boxes, and masks. These are the results I got:
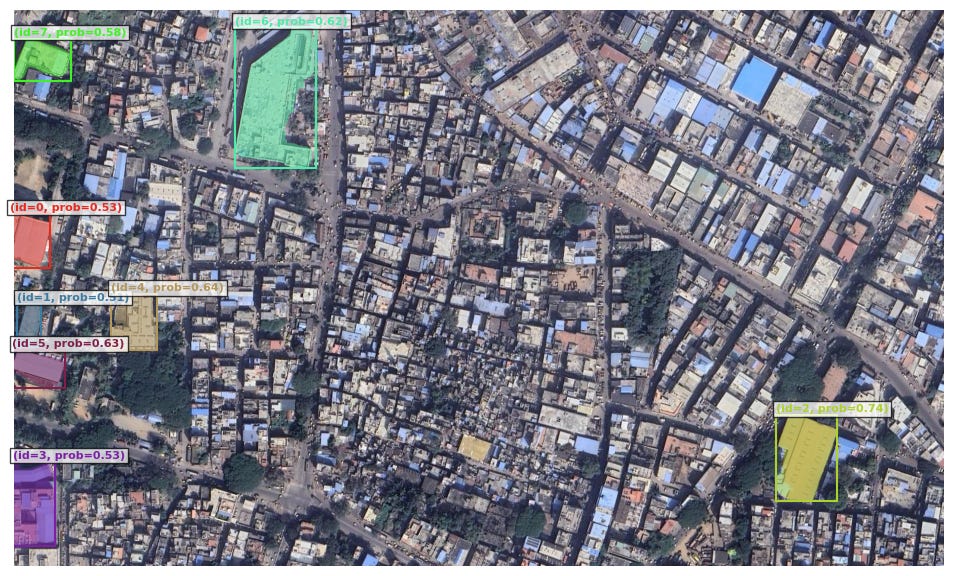
Clearly, there is a lot of progress still needed to make building segmentation better (e.g. for test datasets with different spatial distribution and packing of buildings) because the images in the example/tutorial looked a bit better than real-world (e.g. from developing countries):

AlphaEarth Foundations Satellite Embeddings
As per AlphaEarth introduction blog, every 10m pixel is know containing a 64-D vector characterizing it:
This first-of-its-kind dataset was generated using AlphaEarth Foundations, Google DeepMind’s new geospatial AI model that assimilates observations across diverse sources of geospatial information, including optical and thermal imagery from Sentinel-2 and Landsat satellites, radar data that can see through clouds, 3D measurements of surface properties, global elevation models, climate information, gravity fields, and descriptive text. Unlike traditional deep learning models that require users to fine-tune weights and run their own inference on clusters of high-end computers, AlphaEarth Foundations was designed to produce information-rich, 64-dimensional geospatial “embeddings” that are suitable for use with Earth Engine’s built-in machine learning classifiers and other pixel-based analysis.
Some of the applications involve change detection and tracking of processeses like urban sprawl, wildfire impacts and recovery, automatic clustering, etc.
The dataset has a super cool feature called similarity search. Similarity searches are an easy way to compare embedding vectors for different locations and quickly identify pixels that have similar environmental and surface conditions to a location of interest. For example, the embedding vector for a 100-square-meter (10 m x 10 m) pixel of an airport runway allows me to find all airports (in the world) bearing a strong similarity to the same.
Tiny Demo 3:
So, I published this app where I put a reference point on an existing airport in Hotan prefecture in China and started eyeballing and using similarity score above a specified threshold found a brand new airport not labelled (as of Dec 9th 2025) on OSM or Google Maps. So here is the Google maps pin which shows this find:

This is unbelievably powerful as you can imagine. My first guess would be that we can easily use it to fill in global missing infrastructure for Open Street Maps for example:
Airports
Railway Stations
Public infrastructure
Prithvi: A Generalist Remote Sensing AI Model
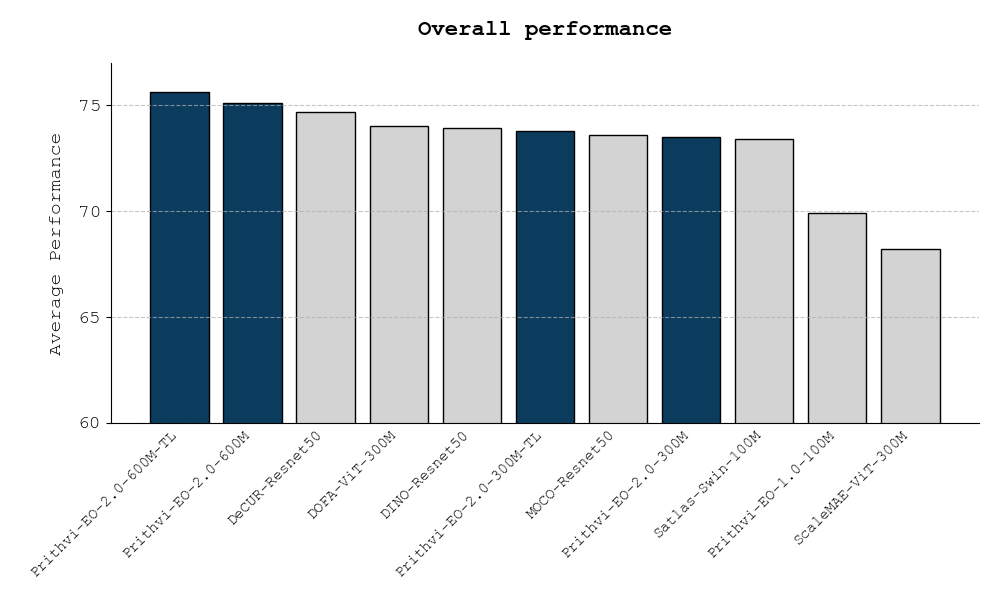
Notable foundation models for “earth monitoring” (basically Earth Observation applications) are being evaluated on the GeoBench benchmark which evaluate models on six classification and segmentation tasks.
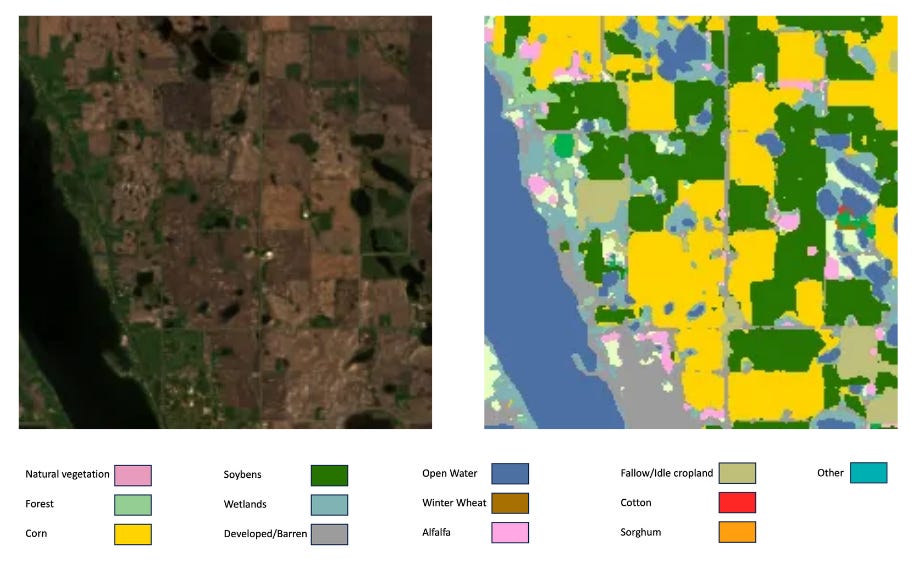
Prithvi is a transformer-based family of geospatial foundational models developed by NASA and IBM. It is pre-trained on multispectral satellite imagery from NASA’s Harmonized Landsat Sentinel-2 (HLS) global dataset. We can perform crop classfication (demo), flood detection and more. The crop classification model requires Blue, Green, Red, Narrow NIR, SWIR, SWIR 2 bands so it is clearly utilizing spectral bands which are more suitable compare to traditional models which just take RGB data.
An exhaustive list of foundation models are found here.
Research Question
Can foundational Earth models such as AlphaEarth can be extended to autonomously detect, vectorize, and update new infrastructure from continuous satellite imagery? I wonder where this can naturally extend to. The central question is:
Can large-scale geospatial AI models continuously identify and convert emerging infrastructure into structured map vectors, creating a self-updating map of Earth?
Recent advances like AlphaEarth, SatCLIP, and Segment-Anything Geospatial (SAMGeo) have shown that foundation models can learn rich spatial-semantic embeddings across modalities. Building on this, the proposed framework introduces a closed-loop pipeline for automated infrastructure discovery:
Detection of Emerging Infrastructure
AlphaEarth’s similarty search modeling capacity is harnessed to analyze recent satellite imagery and detect morphological changes indicating human activity—such as new roads, construction, or urban expansion. We can then choose prompt-based inputs for say identifying the infrastructure segmentation mask. This stage could use unsupervised or semi-supervised similarity-search detection to identify genuinely new structures.Conversion to Map Vectors
Inspired by HPix, SAT2MAP and other image-to-map translation methods, detected contiguous regions that exceed defined spatial thresholds (e.g., >500 m² for buildings, >2 km for roads) are converted into vectorized map features. This step transforms pixel-level detections into GIS-ready data, aligning them with existing cartographic layers. This probably requires some human QA today.Continuous Updating and Validation
New imagery is continuously compared to prior map states. Detected differences trigger localized updates, forming a self-correcting mapping loop. External data (e.g., OpenStreetMap, construction records) provide validation signals to refine confidence and accuracy.
{kind=link}
By merging AlphaEarth’s multimodal perception, SAM-Geo’s segmentation capabilities with HPix/SAT2MAP-style translation and dynamic updating, this system would enable autonomous, continuously evolving digital maps. The implications are vast: near-real-time urban monitoring, disaster response with instant map regeneration, detection of unauthorized development, and improved situational awareness for autonomous systems.